python爬虫学习(四)
scrapy框架
1. 概念
在网络数据采集的领域,Scrapy无疑是一款强大而高效的爬虫框架。它为用户提供了丰富的功能,能够快速抓取和解析网站数据。无论是简单的网页抓取还是复杂的数据提取,Scrapy都能助你一臂之力。
| requests | scrapy |
|---|---|
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般制定灵活,深度制定困难 |
| 上手十分简单 | 入门稍难 |
| 相关图如下: | |
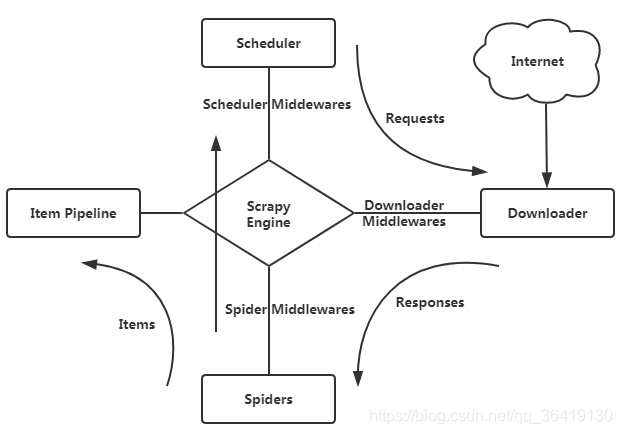 |
- Spiders:中文可以称为蜘蛛,Spiders 是一个复数的统称,其可以对应多个 Spider,每个 Spider 里面定义了站点的爬取逻辑和页面的解析规则。
- Scrapy Engine:引擎,是整个框架的核心。可以理解为整个框架的中央处理器(类似人的大脑),负责数据的流转和逻辑的处理。
- Scheduler:调度器,它用来接受 Engine 发过来的 Request 并将其加入队列中,同时也可以将 Request 发回给 Engine 供 Downloader 执行
- Downloader:下载器,完成向服务器发送请求,然后拿到响应的过程,并发送给Egine
- Item pipeline:管道,用于处理抽取的数据,例如数据清洗、保存到数据库等。
- Item:它是一个抽象的数据结构,所以在图中没有体现出来,它定义了爬取结果的数据结构,爬取的数据会被赋值成 Item 对象。
2.豆瓣电影爬取
网址:https://movie.douban.com/
先下载scrapy相关
1 | pip install scrapy |
下载完成后,先创建一个scrapy项目,在你想要创建的文件夹中cmd打开,并输入
1 | scrapy startproject 你的项目名 |
之后cmd’中会提示你进行
1 | cd 你的项目名 |
创建完项目之后,用pycharm打开即可,之后可以先去分析网址,我认为这一步是尤为重要的,尤其是在scrapy框架此类工具帮助下,代码的书写越来越简单,对网页的分析占比在一次爬虫任务中更为重要。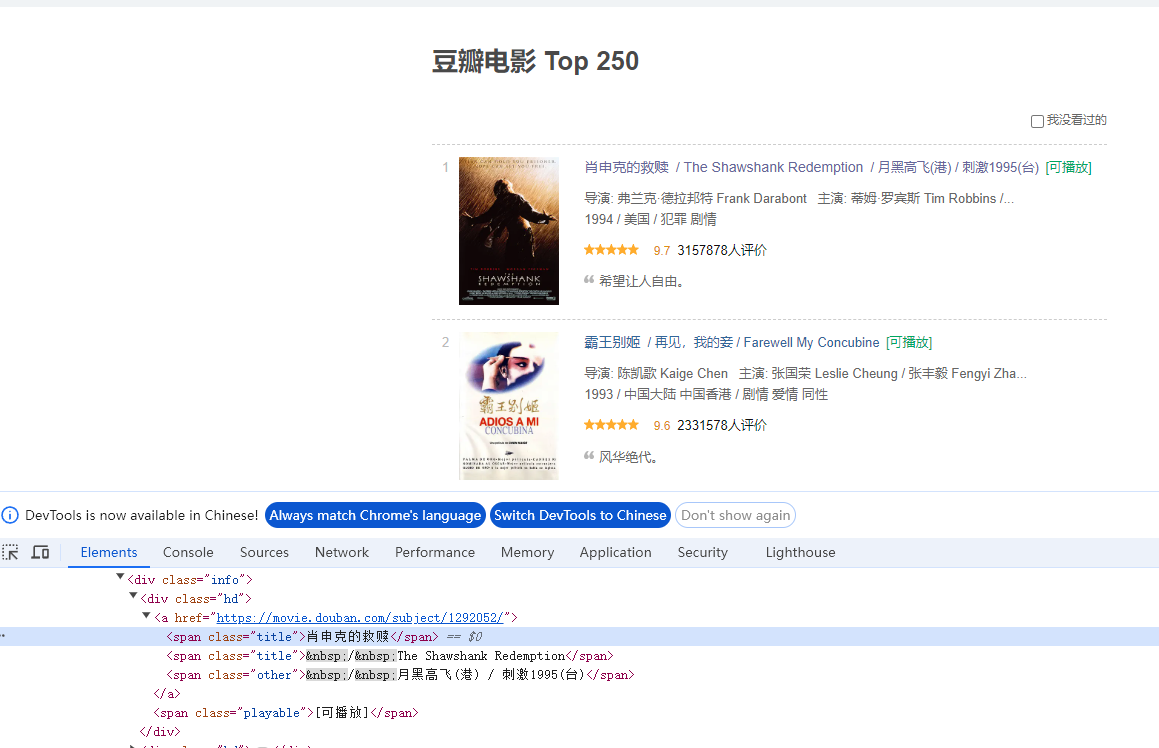
2.1 items.py
通过开发者模式将想要爬取的数据进行定位,确定要爬取哪些信息,然后在items.py中写入对应的对象。
1 | class DoubanItem(scrapy.Item): |
2.2 db.py (自己命名的那个)
完成items的代码后,开始常规上的第一步,也就是对你的db.py进行编写代码
1 | name = "db" |
上述这个代码是你在先前scrapy genspider example example.com 时就会默认生成的,可以根据实际需求进行更改。
而完成另外一个parse方法则是这个文件中最为关键的一步。parse 是 Scrapy 中的默认解析方法,爬虫启动后,Scrapy 会自动下载 start_urls 中的页面,并将响应传递给这个方法。在这里,我们会使用 XPath 来提取电影信息。(这些与requests的获取响应数据类似)
- 首先使用
Selector对页面进行解析。
- 首先使用
- 然后使用 XPath 提取页面中所有电影的列表,遍历每部电影并提取需要的字段信息,如电影的排名、名称、简介、评分等。
- 最后通过
yield返回提取到的数据。获得页面数据列表后就需要对其进行遍历,根据先前在items中已经建立好的对象1
2def parse(self, response): sel = Selector(response) # 使用 Selector 解析 HTML 响应
movie_items = sel.xpath('//div[@class="article"]//ol[@class="grid_view"]/li') # 提取所有电影条目由于这样获得数据仅仅是一页的数据,所以我们还需要进行分页处理,确保获得所有的数据。豆瓣电影的 Top 250 列表分成了 10 页,每页显示 25 部电影。在爬取完第一页后,我们需要继续爬取剩下的页面。通过提取页面底部的“下一页”链接,来实现分页抓取。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from douban.items import DoubanItem
#并且留意整个项目代码希望是完整独立的,不要嵌套在别的文件夹中,这会导致引用包时出现错误
for movie in movie_items:
item = DoubanItem() # 创建 item 实例
# 提取电影信息
item['rank'] = movie.xpath('.//div[@class="pic"]/em/text()').extract_first()
item['movie_name'] = movie.xpath('.//div[@class="hd"]//span[1]/text()').extract_first()
item['movie_quote'] = movie.xpath('.//div[@class="bd"]/p[@class="quote"]/span/text()').extract_first(
default='无')
item['picture'] = movie.xpath('.//div[@class="pic"]/a/img/@src').extract_first()
item['movie_rating'] = movie.xpath('.//div[@class="bd"]/div/span[2]/text()').extract_first()
item['evaluators'] = movie.xpath('.//div[@class="bd"]/div/span[4]/text()').extract_first()
yield item # 返回 item如果你习惯于cmd可以不用这个代码,但是如果你习惯于直接用pycharm去运行程序,须在代码中添加1
2
3next_link = sel.xpath('//span[@class="next"]/link/@href').extract_first()
if next_link:
yield Request(url=response.urljoin(next_link), callback=self.parse)1
2
3
4
5from scrapy import cmdline
if __name__ == '__main__':
#所写的‘db’是与上述的name相同
cmdline.execute('scrapy crawl db'.split())
- 最后通过
下述为db.py的完整代码
1 | import scrapy |
2.3 pipelines.py
在 Scrapy 中,pipelines.py 文件用于处理爬取到的数据。这里,我们要将抓取到的豆瓣电影数据保存到 Excel 文件中。为了实现这一点,我们会使用 Python 的 openpyxl 库,它是一个专门用于处理 Excel 文件的库。
DoubanPipeline类DoubanPipeline 类将处理从爬虫传递过来的数据,并将这些数据写入 Excel 文件。Scrapy 中的 Pipeline 类通常有三个方法:open_spider、process_item 和 close_spider。
- **
open_spider**:当爬虫启动时调用,一般用于初始化一些资源。 - **
process_item**:每当爬虫抓取到一个数据项(item)时,都会调用此方法来处理该项数据。 - **
close_spider**:当爬虫结束时调用,用于保存文件或释放资源。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import openpyxl # 导入处理 Excel 文件的库
from .items import DoubanItem # 导入定义好的 Item 数据结构
class DoubanPipeline:
def __init__(self):
"""
初始化方法,在爬虫开始时被调用,初始化 Excel 工作簿和表格。
""" self.wb = openpyxl.Workbook() # 创建一个新的 Excel 工作簿
self.sheet = self.wb.active # 获取工作簿的活动表格
self.sheet.title = '豆瓣电影Top250' # 设置表格的标题
# 在第一行写入表头,表示每列的意义
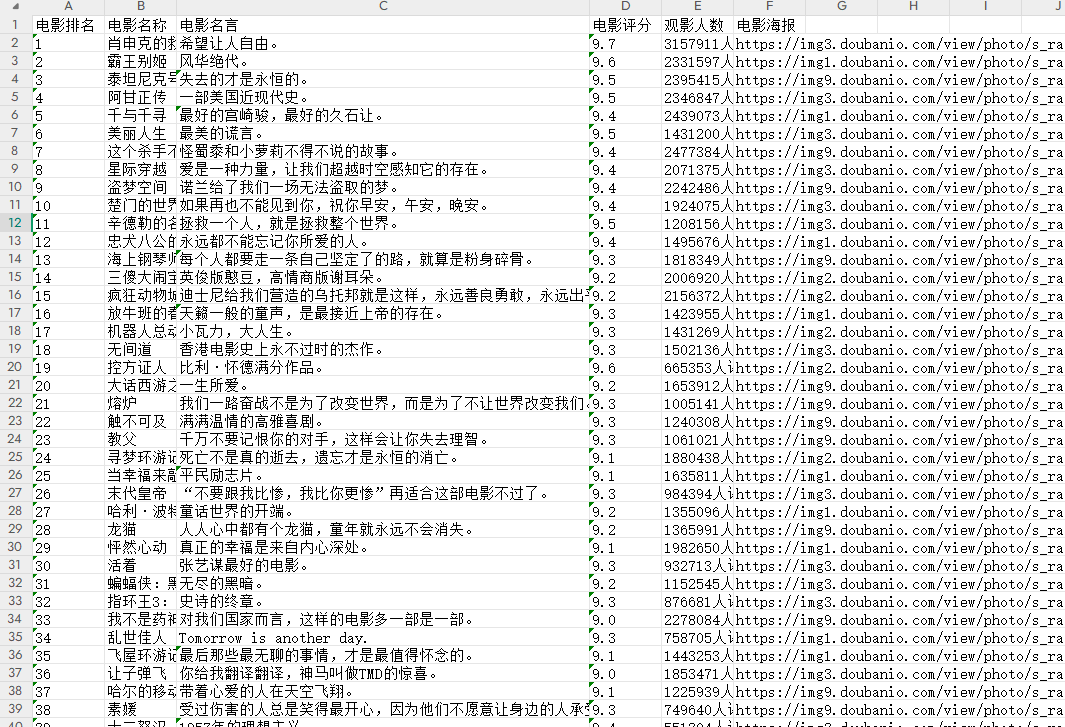
self.sheet.append(('电影排名', '电影名称', '电影名言', '电影评分', '观影人数', '电影海报'))
def open_spider(self, spider):
"""
当爬虫被启动时调用该方法。
:param spider: 当前运行的爬虫对象
""" print('开始爬虫...') # 可以选择在控制台输出提示信息,表示爬虫开始运行
def process_item(self, item: DoubanItem, spider):
"""
处理每个爬取到的数据项(item),将其保存到 Excel 文件中。
:param item: 爬取到的电影数据
:param spider: 当前运行的爬虫对象
:return: 返回处理后的 item """ # 将每部电影的信息以一行的形式写入 Excel self.sheet.append((
item['rank'], # 电影排名
item['movie_name'], # 电影名称
item['movie_quote'], # 电影名言
item['movie_rating'], # 电影评分
item['evaluators'] , # 观影人数
item['picture'] # 电影海报链接
))
# 返回 item 是 Scrapy Pipeline 的标准流程,方便后续可能有其他 pipeline 处理
return item
def close_spider(self, spider):
"""
当爬虫关闭时调用,保存 Excel 文件。
:param spider: 当前运行的爬虫对象
""" print("爬虫结束....") # 输出爬虫结束的提示
# 保存 Excel 文件到指定路径
self.wb.save('豆瓣电影数据.xlsx')
2.4 setting.py
setting中是scrapy中的全局配置文件,我会选择出几个较为重要的进行解释说明。
1 | BOT_NAME = "douban" |
BOT_NAME定义了scrapy项目的名称,scrapy会通过这个名称去识别项目,一般默认即可。SPIDER_MODULES定义了爬虫的存放路径NEWSPIDER_MODULE定义了新爬虫的生成的存放路径
1 | # Obey robots.txt rules |
ROBOT协议默认关闭即可
ps: 虽然机器人协议禁止了,但实际开发中仍需要遵循网站爬虫规则,避免给网站带来过多的负担。
1 | # See also autothrottle settings and docs |
下载延迟,通过定义每个请求之间的时间间隔,来避免触发网站的反爬虫机制
1 | DEFAULT_REQUEST_HEADERS = { |
请求头,这个如果尝试过爬虫应该都不陌生,就是代码去访问网站时带的信息,具体怎么获取可以看我之前的文章,比较基础。
1 | ITEM_PIPELINES = { |
重要,这是开启pipeline的代码,一定要开,不然pipelines就无法使用。300 是该 Pipeline 的优先级,数字越小优先级越高。这里我们设置为 300,表示优先处理该 Pipeline。
1 | # Set settings whose default value is deprecated to a future-proof value |
REQUEST_FINGERPRINTER_IMPLEMENTATION 和 TWISTED_REACTOR,它们是 Scrapy 的内部配置,用于确保兼容性和性能优化。一般创建项目时默认生成,不需要改。
然后在终端运行,或如我写的那样就可在pycharm直接运行,得到如下结果,